- Utilisation de la diffusion. [1] La diffusion n'est pas réellement un protocole, il s'agit plus d'une technique utilisée quelque soit le protocole sous-jacent.
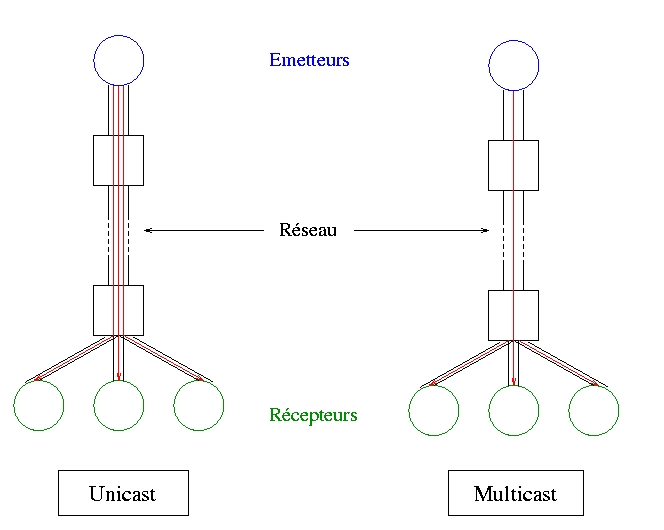
- Le protocole DIS (Distributed Interactive Simulation). [2, 3] L'idée de ce protocole est d'utiliser au mieux la bande passante disponible: au lieu d'envoyer un message à toutes les simulations, on envoie un message à chaque domaine (cf. figure 1). Car en fait les simulations ne sont pas toutes sur le même réseau (e.g Ethernet), mais sont quand même regroupées dans un nombre restreint de domaines. Cette définition correspond au protocole UDP Multicast dont la plus importante implémentation est la DIS (Distributed Interactive Simulation). Elle a été longtemps utilisées comme standard pour les réseaux de simulateurs employés par l'armée.
- Il est possible de perdre des paquets, en effet le protocole ne garantit en rien l'arrivée des messages aux destinataires. Ce problème est important car en admettant que les simulateurs numérotent les paquets qu'ils envoient pour avoir une synchronisation minimale, étant donné que l'envoi des messages n'est pas continu, il peut y avoir un temps de latence plus ou moins important entre l'instant d'émission du message et le moment où l'un des simulateur se rend compte qu'il lui manque un message.
- La taille des paquets par ce protocole est fixe. C'est inaproprié, car des transformations peuvent etre basées sur un grand nombre de données, et donc nécessiter la communication d'un plus ou moins grand nombre d'informations.
- Le dernier problème concerne directement l'utilisation de la diffusion, qui va sérieusement limiter l'extension de ce protocole lorsqu'un trés grand nombre d'intervenants sont répartis sur des domaines très différents.
- Le protocole HLA (High Level Architecture). Il y a un grand nombre de différences entre DIS et HLA, tout d'abord, HLA est une architecture de haut niveau, elle ne dépend pas d'un unique protocole de communication. On va retrouver de cette façon le même type de couches que pour le développement basé sur Open-Inventor, lui même basé sur OpenGL: on peut modifier la façon dont OpenGL va permettre de stocker un élément sans rien modifier d'autre.
- Implémentations et autres protocoles. [4] On peut citer le protocole Living Worlds (LW): il sagit de réflexions menées par un groupe de travail du consortium VRML qui visait à définir des normes et standards pour le VRML 2.0 permettant la gestion d'environnements collaboratifs. Ce n'est pas vraiment un protocole de communication, mais c'est la première réflexion pour rechercher un standard dans le domaine des environnements virtuels collaboratifs.
En effet lorsque l'environnement est modifié par une des simulations, celle-ci doit diffuser à toutes les autres les modifications effectuées. De cette façon, les autres simulations sont alors responsables de l'utilisation des données qu'elles ont reçu. Le problème inhérent à cette technique est la saturation du réseau qui risque de survenir dès qu'un certain nombre de simulations ont lieu.
Le modèle DIS a donc été défini afin de permettre une extension du modèle de la diffusion.
Le dernier principe réside dans le fait qu'il faut limiter les informations transitant sur le réseau, chaque simulateur ayant en fait la partie de la base de donnée qui lui est nécessaire, et ensuite seules sont envoyées les modifications effectuées dans la base. De cette façon, tous les simulateurs ont toujours toutes les données dont ils ont besoin sans avoir une duplication complète de la base de données.
Cependant, ce protocole pose de nombreux problèmes :
Une nouvelle solution a donc été envisagée, indépendante des protocoles de bas niveau, et permettant plus de liberté.
Cette architecture a été largement utilisée. Elle gère le multicast mais ajoute en plus la condition de fiabilité nécessaire aux applications collaboratives. Cette architecture normalise une interface, ce qui fait que le développement d'applications est plus simple alors qu'auparavant la couche DIS restait difficile à utiliser. Cette architecture peut être utilisée sur un réseau hétérogène, et permet le fonctionnement d'applications avec ou sans temps réel, la communication n'étant plus seulement entre simulateurs, mais aussi avec des applications pilotées.
Le principal problème qui se présente est que lorsque l'on introduit les environnements virtuels ou immersifs, les volumes de messages induits par ces applications sont beaucoup plus importants. Cela implique l'utilisation de réseaux trés performants. Toujours est-il que cette architecture a été développée par le département de la DMSO (U.S. Defense Modeling and Simulation Office) et est actuellement en train de devenir un standard normalisé par IEEE. L'implémentation RTI (HLA's Runtime Infrastructure) est développée sur un certain nombre de systèmes, et fourni un ensemble d'outils respectant les services précédemment définis.
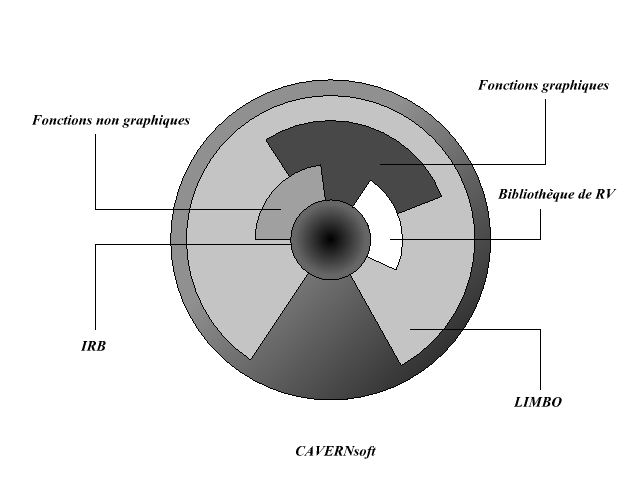
Au niveau des implémentations, l'une des plus importantes, est l'ensemble d'outils fournis par l'API CAVERNsoft (CAVE Research Network). Il s'agit d'un ensemble de fonctionnalités permettant de mettre en relation des applications basées sur les CAVEs.
Les fonctions sont réparties suivant le modèle suivant :
L'Open Community a proposé un standard pour la collaboration utilisant des technologies de Mitsubishi Electric Research Laboratories. L'implémentation qui a suivi, SPLINE (Scalable Platform for Large Interactive Networked Environments) a été réalisée en ANSI C et sous forme d'une API Java. Cette API est la seule permettant de paramètrer le temps entre les différentes mises à jour.
La dernière que l'on peut siter est une API Java, JSDT (Java Shared Data Toolkit), elle n'a pas été créée spécifiquement pour les environnements 3D, mais fourni de nombreux outils pour la réalisation d'applications collaboratives et multimédia.
Toutes ces bibliothèques n'ont plus besoins d'être présentées en détail, mais on va examiner une comparaison des performances entres les différents protocoles réseau et les bibliothèques graphiques pour mettre en valeur les temps de latence (un temps de latence est convenable lorsqu'il se situe autour des 200ms, ou vers les 100ms lorsque ce sont des applications critiques temps-réel).
L'évaluation des performances s'effectue sur quatre niveaux :
- L'affichage, le délai inhérent au matériel, moniteurs, projecteurs...
- Le délai dû au rendu graphique, en général dépendant des cartes et drivers utilisés.
- La simulation, le temps utilisés par le processeur pour les processus de gestion de l'environnement colaboratif lui-même.
- L'interconnexion, le temps pris pour les communications.
| RTI & VRML; | RTI & Java3D; | JSDT | SPLINE & VRML (MAJ 100ms); | SPLINE & VRML (MAJ 1ms); | |
| CC | 184 | 152 | - | 129 | 68 |
| Communication | 103 | 103 | 60 | 85 | 12 |
| OT | 235 | 204 | 5 | 217 | 78 |
- CC : temps mis entre la modification d'un objet et la mise à jour chez un autre utilisateur, ce délai inclut le rendu.
- Communication : temps CC moins le temps mis par le rendu.
- OT : temps mis par certains protocoles pour la vérification d'interblocages (c'est le cas de RTI et SPLINE).
En conclusion, on peut constater que SPLINE et RTI sont des protocoles satisfaisants qui permettent de bons compromis. Par exemple, lorsque l'on veut modifier un objet, il y a d'abord un envoi de message pour vérifier si l'objet est en train d'être modifié ailleurs: cette demande prend du temps mais ajoute une sécurité absente des autres protocoles réseau, d'où une grande différence de latence.
JSDT parait trés rapide. Cependant, cette API ne contient aucune fonctionalité 3D, nous obligeant à tout réimplémenter. Java3D introduit une latence de 50 à 80 ms, car il y a une interface entre le langage interprété et le langage natif, ce qui peut être évité si l'API est associée à l'API JSTD. Cette association est une bonne solution pour les application demandant un temps de réponse très court et ne nécessitant pas de vérification trop importante des interblocages.
Ces différents tests ont été effectués dans des conditions idéales, avec un nombre restreint d'utilisateurs; si on veut utiliser ce type d'application via Internet, les temps deviendrait trop important pour permettre une bonne utilisation d'un tel environnement. Aussi, si le nombre d'intervenants devient important, il faut disposer d'un réseau capable de supporter les fortes charges qui en résulteront.